Go从零实现 - 分布式缓存 - GeeCache
缓存淘汰策略、LRU 实现
存储是优先的,满了去掉谁
LFU(Least Frequently Used)
访问次数,去掉访问最少的
- 内存占用大
- 受已有模式影响多
LRU(Least Recently Used)
LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。
LRU 实现
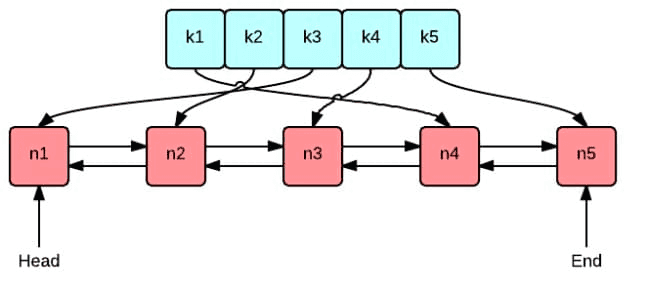
整体逻辑并不复杂,包装 entry 是为了删除队尾的时候方便
delete(c.cache, kv.key)
package lru
import "container/list"
type Value interface {
Len() int
}
type Cache struct {
maxBytes int64
nbytes int64
// 使用双向链表
ll *list.List
// 使用 map
cache map[string]*list.Element
OnEvicted func(key string, value Value)
}
func New(maxBytes int64, onEvicted func(string2 string, value Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: onEvicted,
}
}
type entry struct {
key string
value Value
}
func (c *Cache) Add(key string, value Value) {
if ele, ok := c.cache[key]; ok {
// LRU 调整顺序到头部 头部是最近使用的,尾部是最久未使用的
c.ll.MoveToFront(ele)
c.nbytes += int64(len(key)) + int64(value.Len())
kv := ele.Value.(*entry)
kv.value = value
} else {
// 新增
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
c.nbytes += int64(len(key)) + int64(value.Len())
}
for c.maxBytes != 0 && c.maxBytes < c.nbytes {
c.RemoveOldest()
}
}
func (c *Cache) RemoveOldest() {
ele := c.ll.Back()
if ele == nil {
return
}
c.ll.Remove(ele)
kv := ele.Value.(*entry)
delete(c.cache, kv.key)
c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len())
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
func (c *Cache) Get(key string) (value Value, ok bool) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele)
kv := ele.Value.(*entry)
return kv.value, true
}
return
}
func (c *Cache) Len() int {
return c.ll.Len()
}
单机并发缓存
为现有的 Cache 增加并发读取的能力
先看看使用层
func TestGet(t *testing.T) {
loadCounts := make(map[string]int, len(db))
gee := NewGroup("scores", 2<<10, GetterFunc(
func(key string) ([]byte, error) {
log.Println("[SlowDB] search key", key)
if v, ok := db[key]; ok {
if _, ok := loadCounts[key]; !ok {
loadCounts[key] = 0
}
loadCounts[key] += 1
return []byte(v), nil
}
return nil, fmt.Errorf("%s not exist", key)
}))
for k, v := range db {
if view, err := gee.Get(k); err != nil || view.String() != v {
t.Fatal("failed to get value of Tom")
} // load from callback function
if _, err := gee.Get(k); err != nil || loadCounts[k] > 1 {
t.Fatalf("cache %s miss", k)
} // cache hit
}
if view, err := gee.Get("unknown"); err == nil {
t.Fatalf("the value of unknow should be empty, but %s got", view)
}
}NewGroup 创建返回 gee,也就是缓存实例,创建的时候第三个参数是缓存未命中时的获取逻辑,获取到了,拿到的结果会加入缓存
NewGroup 的 核心 Get 实现
// A Getter loads data for a key.
type Getter interface {
Get(key string) ([]byte, error)
}
// A GetterFunc implements Getter with a function.
type GetterFunc func(key string) ([]byte, error)
// Get implements Getter interface function
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
}
// A Group is a cache namespace and associated data loaded spread over
type Group struct {
name string
getter Getter
mainCache cache
}
// Get value for a key from cache
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
if v, ok := g.mainCache.get(key); ok {
log.Println("[GeeCache] hit")
return v, nil
}
return g.load(key)
}
func (g *Group) load(key string) (value ByteView, err error) {
return g.getLocally(key)
}
func (g *Group) getLocally(key string) (ByteView, error) {
bytes, err := g.getter.Get(key)
if err != nil {
return ByteView{}, err
}
value := ByteView{b: cloneBytes(bytes)}
g.populateCache(key, value)
return value, nil
}
func (g *Group) populateCache(key string, value ByteView) {
g.mainCache.add(key, value)
}Getter 这里接口型函数的设计可看
cache 的实现
package geecache
import (
"geecache/lru"
"sync"
)
type cache struct {
mu sync.Mutex
lru *lru.Cache
cacheBytes int64
}
func (c *cache) add(key string, value ByteView) {
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil {
c.lru = lru.New(c.cacheBytes, nil)
}
c.lru.Add(key, value)
}
func (c *cache) get(key string) (value ByteView, ok bool) {
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil {
return
}
if v, ok := c.lru.Get(key); ok {
return v.(ByteView), ok
}
return
}这里为 lru 的读取套上了一层锁的机制
Note
多个协程(goroutine)同时读写同一个变量,在并发度较高的情况下,会发生冲突。确保一次只有一个协程(goroutine)可以访问该变量以避免冲突,这称之为互斥,互斥锁可以解决这个问题。
sync.Mutex 是一个互斥锁,可以由不同的协程加锁和解锁。
sync.Mutex 是 Go 语言标准库提供的一个互斥锁,当一个协程(goroutine)获得了这个锁的拥有权后,其它请求锁的协程(goroutine) 就会阻塞在 Lock() 方法的调用上,直到调用 Unlock() 锁被释放。
byte 是很通用的存储结构,抽象一层这个结构,并满足我们 Value 的接口要求
// Value use Len to count how many bytes it takes
type Value interface {
Len() int
}
package geecache
// A ByteView holds an immutable view of bytes.
type ByteView struct {
b []byte
}
// Len returns the view's length
func (v ByteView) Len() int {
return len(v.b)
}
// ByteSlice returns a copy of the data as a byte slice.
func (v ByteView) ByteSlice() []byte {
return cloneBytes(v.b)
}
// String returns the data as a string, making a copy if necessary.
func (v ByteView) String() string {
return string(v.b)
}
func cloneBytes(b []byte) []byte {
c := make([]byte, len(b))
copy(c, b)
return c
}至此整体结构
geecache/
|--lru/
|--lru.go // lru 缓存淘汰策略
|--byteview.go // 缓存值的抽象与封装
|--cache.go // 并发控制
|--geecache.go // 负责与外部交互,控制缓存存储和获取的主流程至此,这一章节的单机并发缓存就已经完成了。
HTTP 服务端
Note
分布式缓存需要实现节点间通信,建立基于 HTTP 的通信机制是比较常见和简单的做法。如果一个节点启动了 HTTP 服务,那么这个节点就可以被其他节点访问。今天我们就为单机节点搭建 HTTP Server。
目标是可以通过 HTTP 协议访问到 上面实现的 geecache
使用层为
func main() {
geecache.NewGroup("scores", 2<<10, geecache.GetterFunc(
func(key string) ([]byte, error) {
log.Println("[SlowDB] search key", key)
if v, ok := db[key]; ok {
return []byte(v), nil
}
return nil, fmt.Errorf("%s not exist", key)
}))
addr := "localhost:9999"
peers := geecache.NewHTTPPool(addr)
log.Println("geecache is running at", addr)
log.Fatal(http.ListenAndServe(addr, peers))
}启动后可以通过 HTTP 进行访问
$ curl http://localhost:9999/_geecache/scores/Tom
630
$ curl http://localhost:9999/_geecache/scores/kkk
kkk not existURL 格式为 /<basepath>/<groupname>/<key>
通过 groupname 得到 group 实例,再使用 group.Get(key) 获取缓存数据。
peers := geecache.NewHTTPPool(addr)
http.ListenAndServe(addr, peers)peers 需要满足 ListenAndServe 的接口要求
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}因此造一个 HTTPPool 实现 ServeHTTP 接口就好
const defaultBasePath = "/_geecache/"
// HTTPPool implements PeerPicker for a pool of HTTP peers.
type HTTPPool struct {
// this peer's base URL, e.g. "https://example.net:8000"
self string
basePath string
}
// NewHTTPPool initializes an HTTP pool of peers.
func NewHTTPPool(self string) *HTTPPool {
return &HTTPPool{
self: self,
basePath: defaultBasePath,
}
}
// Log info with server name
func (p *HTTPPool) Log(format string, v ...interface{}) {
log.Printf("[Server %s] %s", p.self, fmt.Sprintf(format, v...))
}
// ServeHTTP handle all http requests
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if !strings.HasPrefix(r.URL.Path, p.basePath) {
panic("HTTPPool serving unexpected path: " + r.URL.Path)
}
p.Log("%s %s", r.Method, r.URL.Path)
// /<basepath>/<groupname>/<key> required
parts := strings.SplitN(r.URL.Path[len(p.basePath):], "/", 2)
if len(parts) != 2 {
http.Error(w, "bad request", http.StatusBadRequest)
return
}
groupName := parts[0]
key := parts[1]
group := GetGroup(groupName)
if group == nil {
http.Error(w, "no such group: "+groupName, http.StatusNotFound)
return
}
view, err := group.Get(key)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/octet-stream")
w.Write(view.ByteSlice())
}接下来,运行 main 函数,使用 curl 做一些简单测试:
$ curl http://localhost:9999/_geecache/scores/Tom
630
$ curl http://localhost:9999/_geecache/scores/kkk
kkk not existGeeCache 的日志输出如下:
2020/02/11 23:28:39 geecache is running at localhost:9999
2020/02/11 23:29:08 [Server localhost:9999] GET /_geecache/scores/Tom
2020/02/11 23:29:08 [SlowDB] search key Tom
2020/02/11 23:29:16 [Server localhost:9999] GET /_geecache/scores/kkk
2020/02/11 23:29:16 [SlowDB] search key kkk一致性哈希(hash)
场景
当我们有多个 Cache Server 的时候,一个 key 的请求过来,去哪个 Cache Server 来请求呢 需要满足以下条件
- 缓存命中率高
- 容易拓展
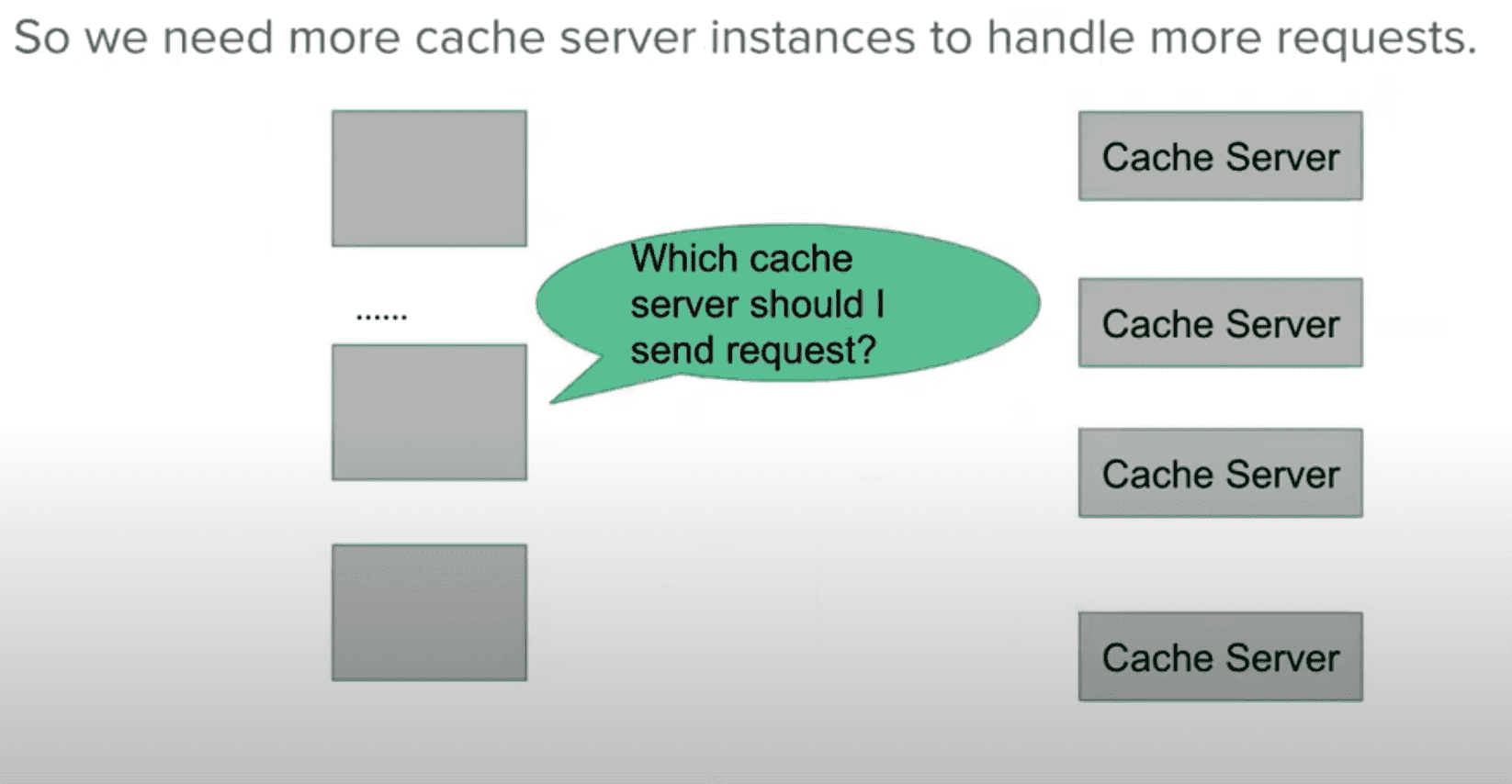
方案
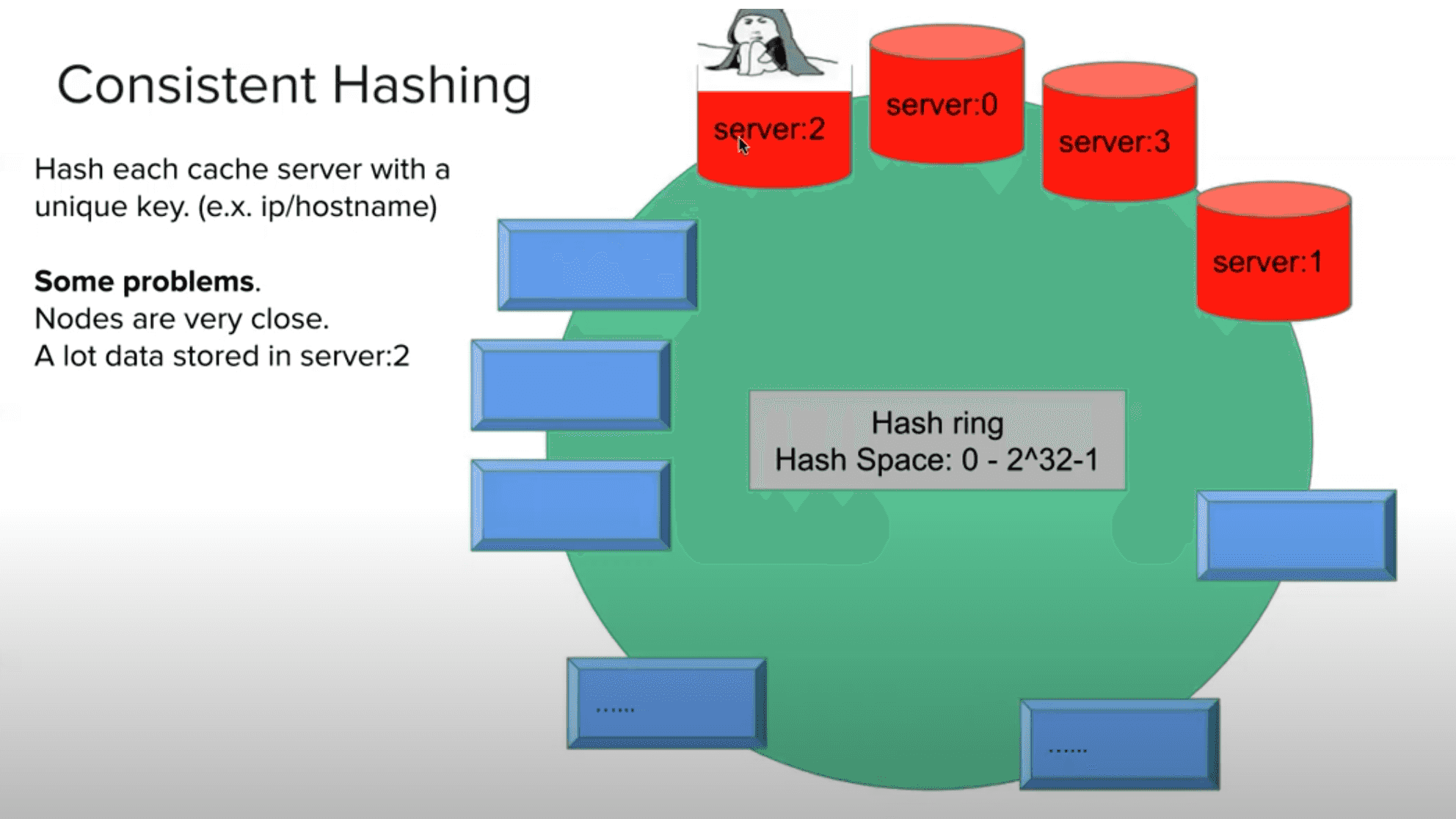
方案 1 如下图
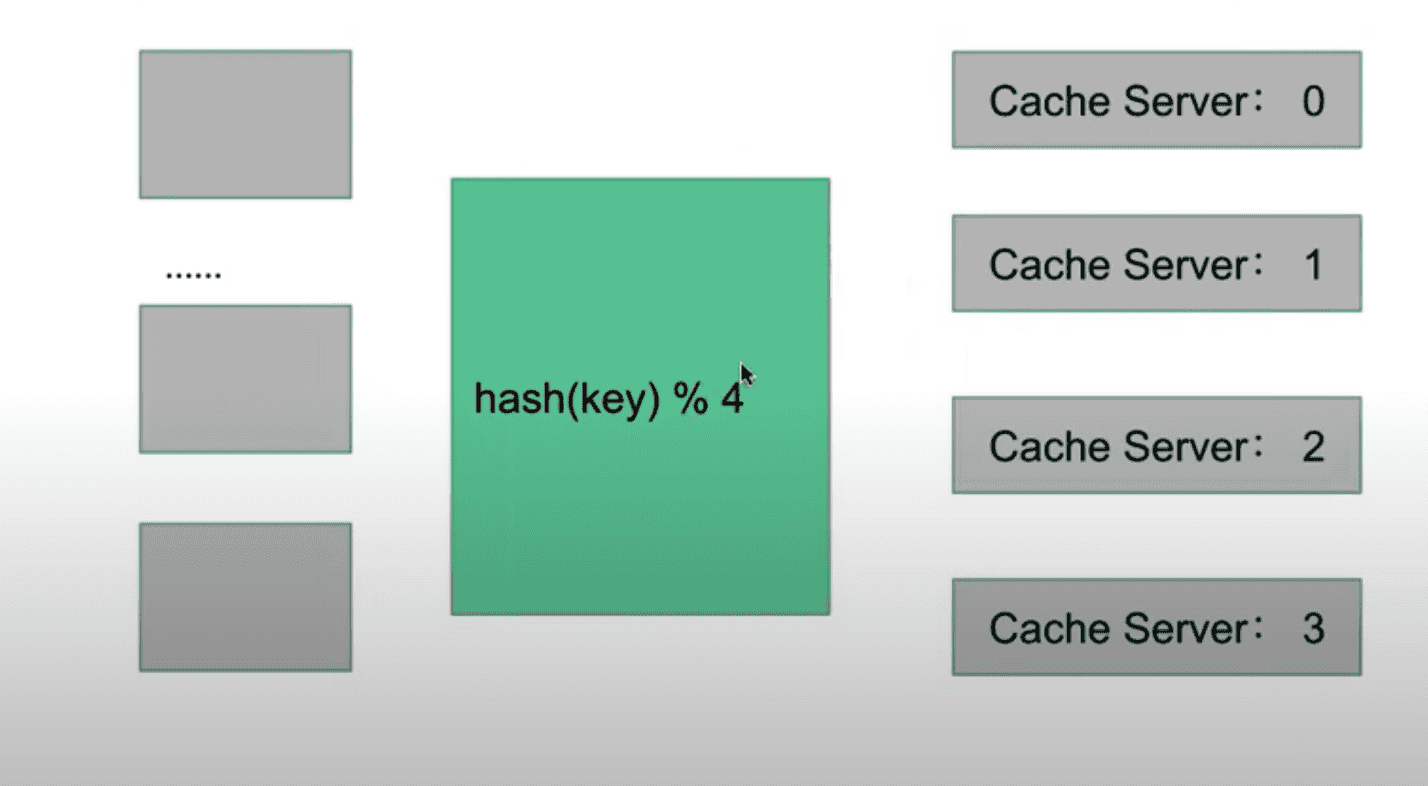 命中率高,算法简单,但是一旦 Cache Server 数量变化,现有缓存都无用了
命中率高,算法简单,但是一旦 Cache Server 数量变化,现有缓存都无用了
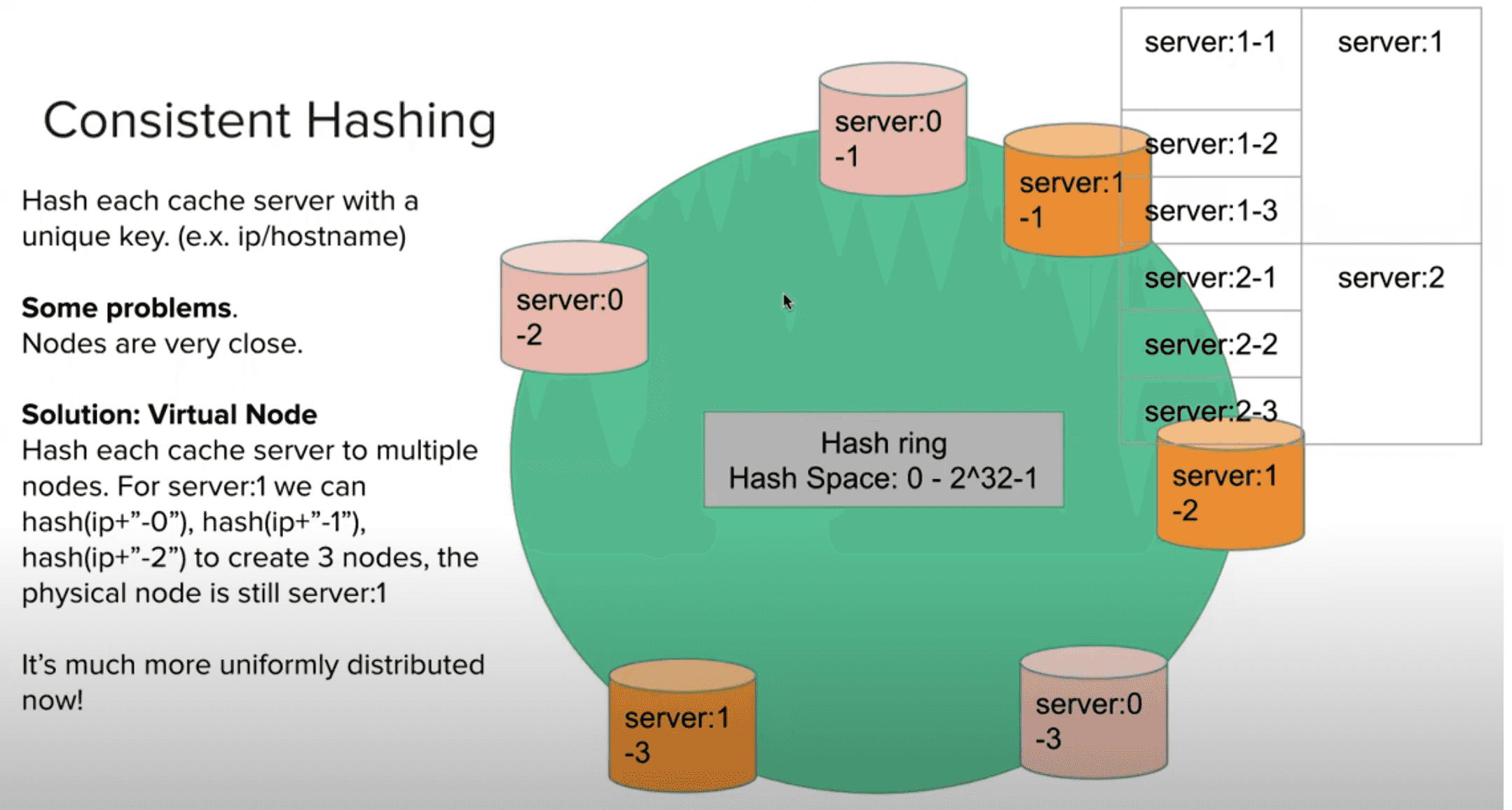
方案 2 一致性哈希
如上图
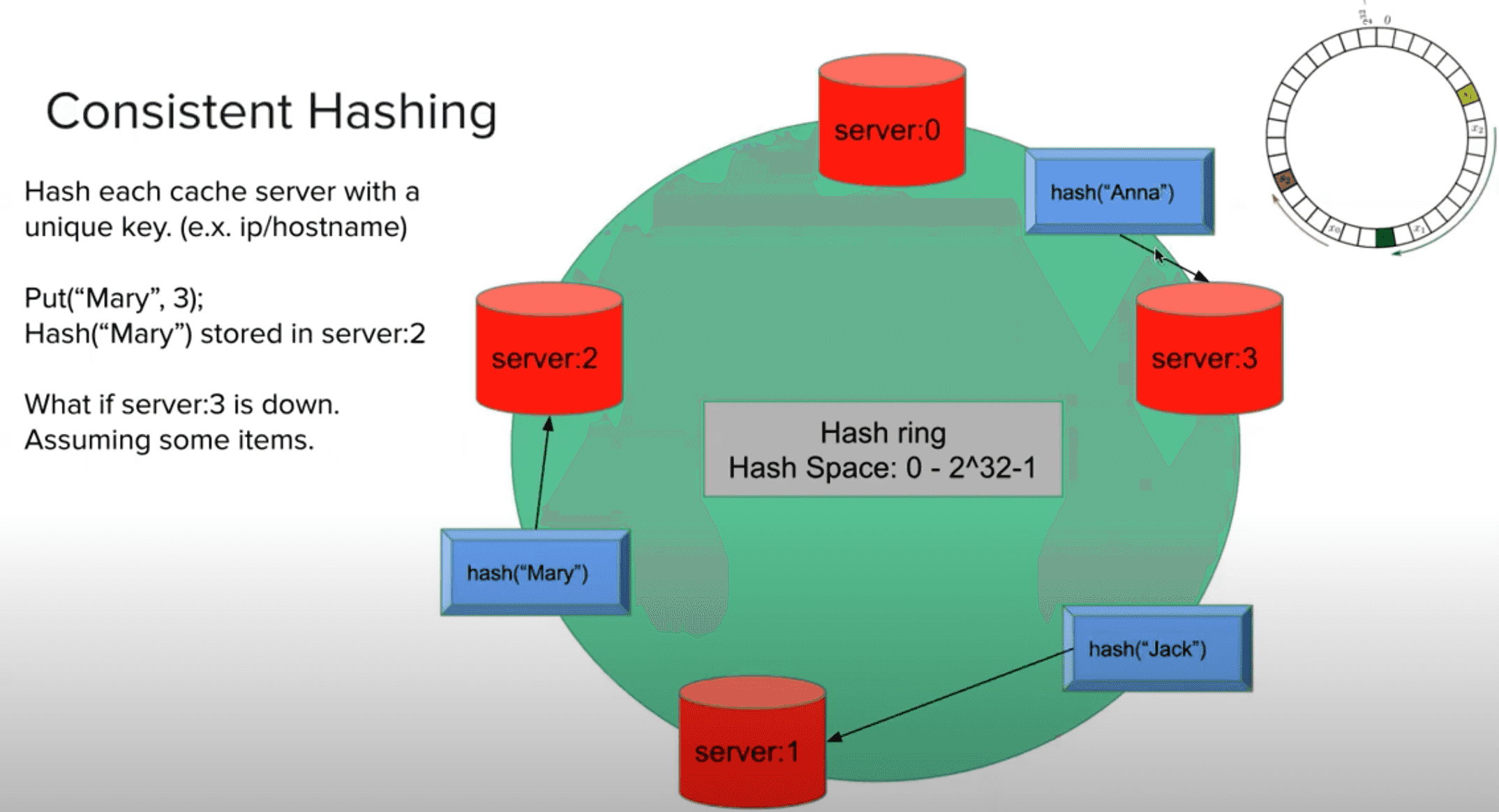
并且为了解决分布不均匀的问题,增加虚拟节点
实现
package consistenthash
import (
"hash/crc32"
"sort"
"strconv"
)
// Hash maps bytes to uint32
type Hash func(data []byte) uint32
// Map constains all hashed keys
type Map struct {
hash Hash
replicas int
keys []int // Sorted
hashMap map[int]string
}
// New creates a Map instance
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas,
hash: fn,
hashMap: make(map[int]string),
}
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
// Add adds some keys to the hash.
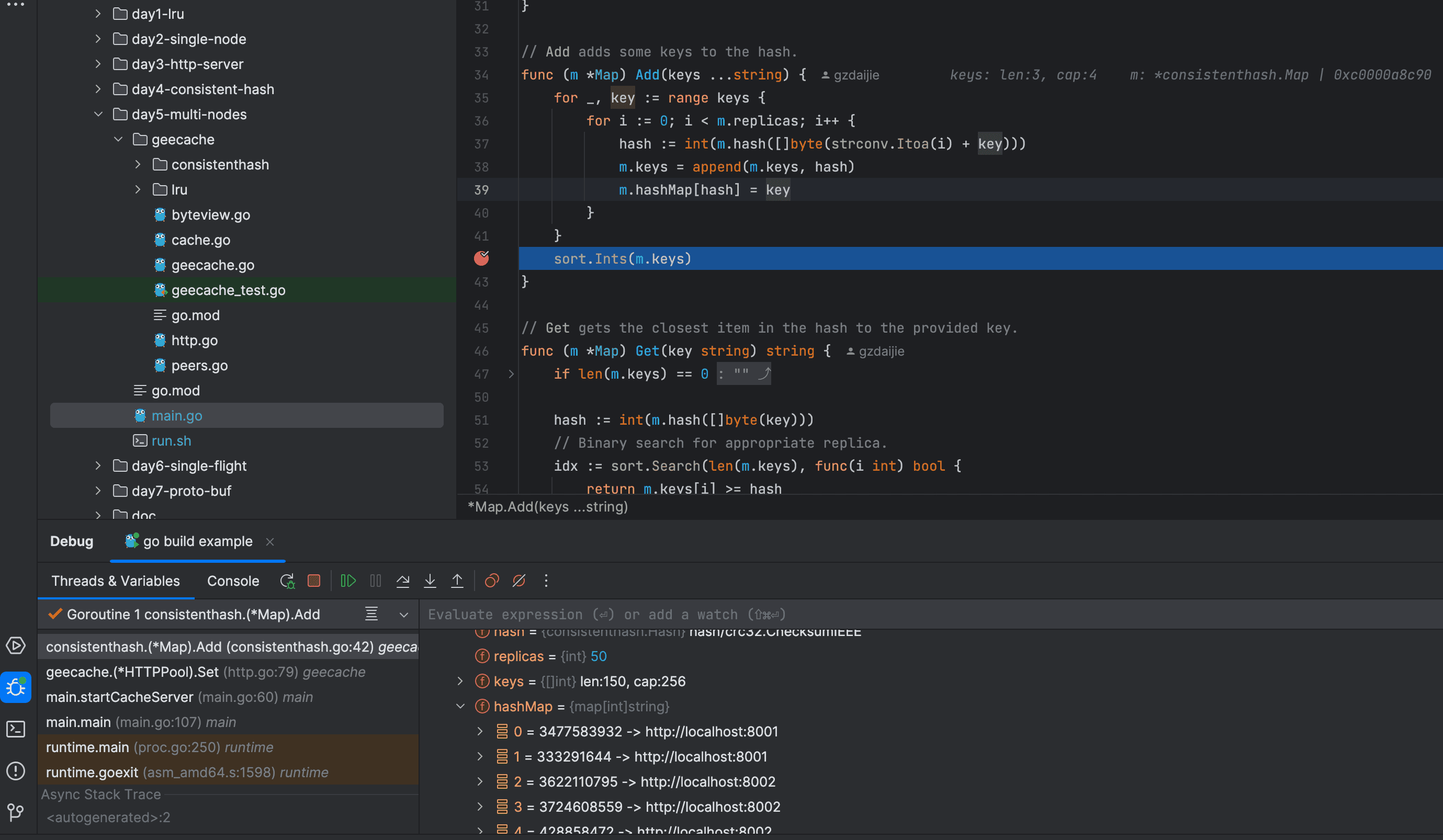
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
// Get gets the closest item in the hash to the provided key.
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
hash := int(m.hash([]byte(key)))
// Binary search for appropriate replica.
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
return m.hashMap[m.keys[idx%len(m.keys)]]
}
最后一行 m.keys[idx%len(m.keys)] 有些理解成本
Note
如果 idx == len(m.keys),说明应选择 m.keys[0],因为 m.keys 是一个环状结构,所以用取余数的方式来处理这种情况。
其他参考
一致性哈希 - Consistent Hashing 是什么?为什么系统设计面试中经常会提到?10 分钟讲解一致性哈希 | 系统设计 System Design EP1
分布式节点
现有流程
现在的流程为
是
接收 key --> 检查是否被缓存 -----> 返回缓存值 ⑴
| 否 是
|-----> 是否应当从远程节点获取 -----> 与远程节点交互 --> 返回缓存值 ⑵
| 否
|-----> 调用`回调函数`,获取值并添加到缓存 --> 返回缓存值 ⑶1、3 已经在 单机并发缓存那里实现,本节主要来解决 2
使用一致性哈希选择节点 是 是
|-----> 是否是远程节点 -----> HTTP 客户端访问远程节点 --> 成功?-----> 服务端返回返回值
| 否 ↓ 否
|----------------------------> 回退到本地节点处理。先看使用层
import (
"flag"
"fmt"
"geecache"
"log"
"net/http"
"strings"
)
var db = map[string]string{
"Tom": "630",
"Jack": "589",
"Sam": "567",
}
func createGroup() *geecache.Group {
return geecache.NewGroup("scores", 2<<10, geecache.GetterFunc(
func(key string) ([]byte, error) {
log.Println("[SlowDB] search key", key)
if v, ok := db[key]; ok {
return []byte(v), nil
}
return nil, fmt.Errorf("%s not exist", key)
}))
}
func startCacheServer(addr string, addrs []string, gee *geecache.Group) {
peers := geecache.NewHTTPPool(addr)
peers.Set(addrs...)
gee.RegisterPeers(peers)
log.Println("geecache is running at", addr)
log.Fatal(http.ListenAndServe(strings.TrimPrefix(addr, "http://"), peers))
}
func startAPIServer(apiAddr string, gee *geecache.Group) {
http.Handle("/api", http.HandlerFunc(
func(w http.ResponseWriter, r *http.Request) {
key := r.URL.Query().Get("key")
view, err := gee.Get(key)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/octet-stream")
w.Write(view.ByteSlice())
}))
log.Println("fontend server is running at", apiAddr)
log.Fatal(http.ListenAndServe(strings.TrimPrefix(apiAddr, "http://"), nil))
}
func main() {
var port int
var api bool
flag.IntVar(&port, "port", 8001, "Geecache server port")
flag.BoolVar(&api, "api", false, "Start a api server?")
flag.Parse()
apiAddr := "http://0.0.0.0:9999"
addrMap := map[int]string{
8001: "http://0.0.0.0:8001",
8002: "http://0.0.0.0:8002",
8003: "http://0.0.0.0:8003",
}
var addrs []string
for _, v := range addrMap {
addrs = append(addrs, v)
}
gee := createGroup()
if api {
go startAPIServer(apiAddr, gee)
}
startCacheServer(addrMap[port], addrs, gee)
}#!/bin/bash
trap "rm server;kill 0" EXIT
go build -o server
./server -port=8001 &
./server -port=8002 &
./server -port=8003 -api=1 &
sleep 2
echo ">>> start test"
curl "http://127.0.0.1:9999/api?key=Tom" &
curl "http://127.0.0.1:9999/api?key=Tom" &
curl "http://127.0.0.1:9999/api?key=Tom" &
wait起了三个 Cache Server,端口分别在 8001 8002 8003 其中有个服务同时起了 Cache Server 和 对外暴露的 API 服务,这个 API 服务放在 9999 端口上
执行结果是
2023/11/22 09:29:09 geecache is running at http://0.0.0.0:8001
2023/11/22 09:29:09 geecache is running at http://0.0.0.0:8002
2023/11/22 09:29:09 fontend server is running at http://0.0.0.0:9999
2023/11/22 09:29:09 geecache is running at http://0.0.0.0:8003
>>> start test
2023/11/22 09:29:11 [Server http://0.0.0.0:8003] Pick peer http://0.0.0.0:8002
2023/11/22 09:29:11 [Server http://0.0.0.0:8003] Pick peer http://0.0.0.0:8002
2023/11/22 09:29:11 [Server http://0.0.0.0:8003] Pick peer http://0.0.0.0:8002
2023/11/22 09:29:11 [Server http://0.0.0.0:8002] GET /_geecache/scores/Tom
2023/11/22 09:29:11 [SlowDB] search key Tom
2023/11/22 09:29:11 [Server http://0.0.0.0:8002] GET /_geecache/scores/Tom
2023/11/22 09:29:11 [GeeCache] hit
2023/11/22 09:29:11 [Server http://0.0.0.0:8002] GET /_geecache/scores/Tom
2023/11/22 09:29:11 [GeeCache] hit
630630630整个流程
如下图
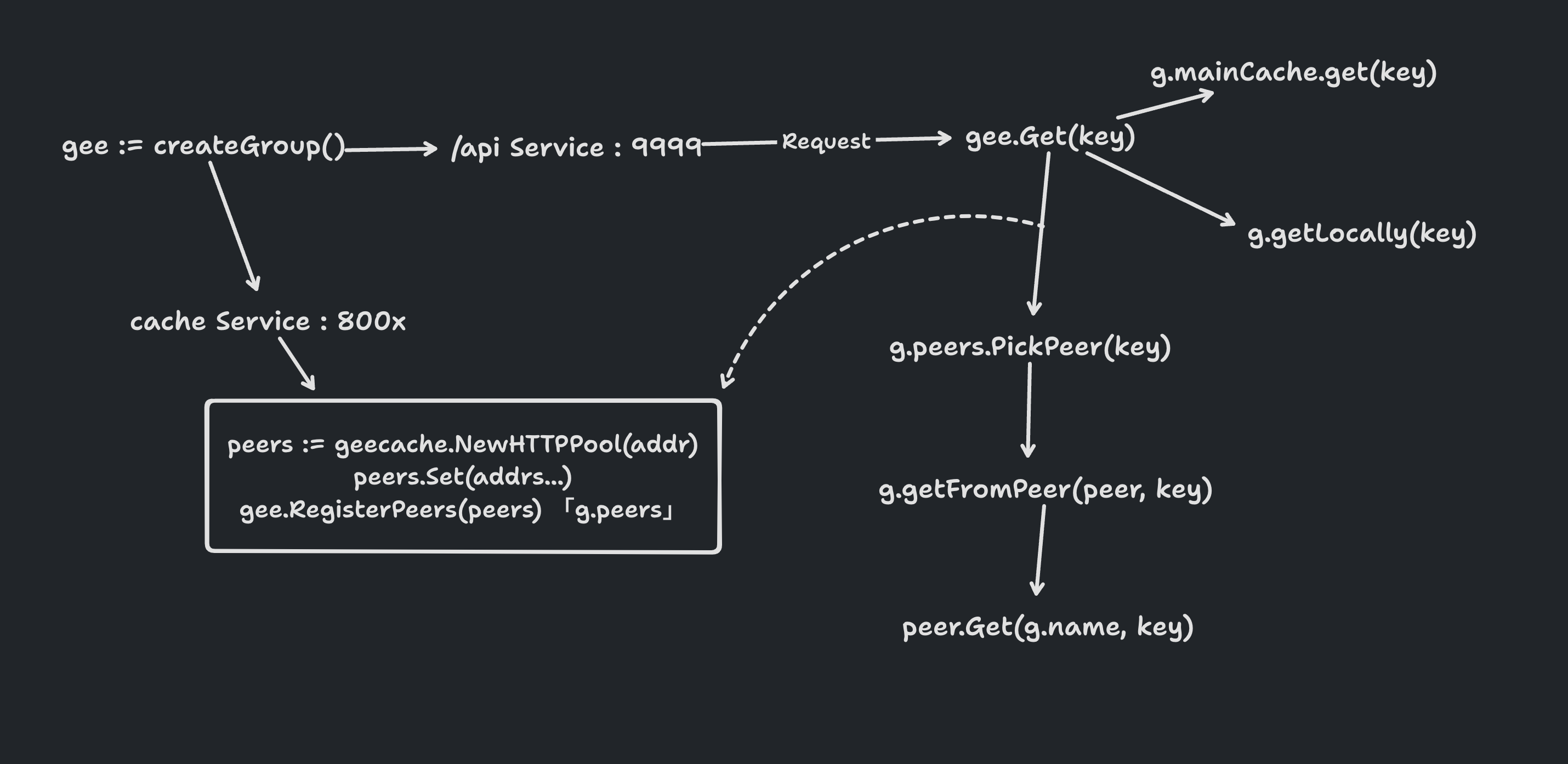
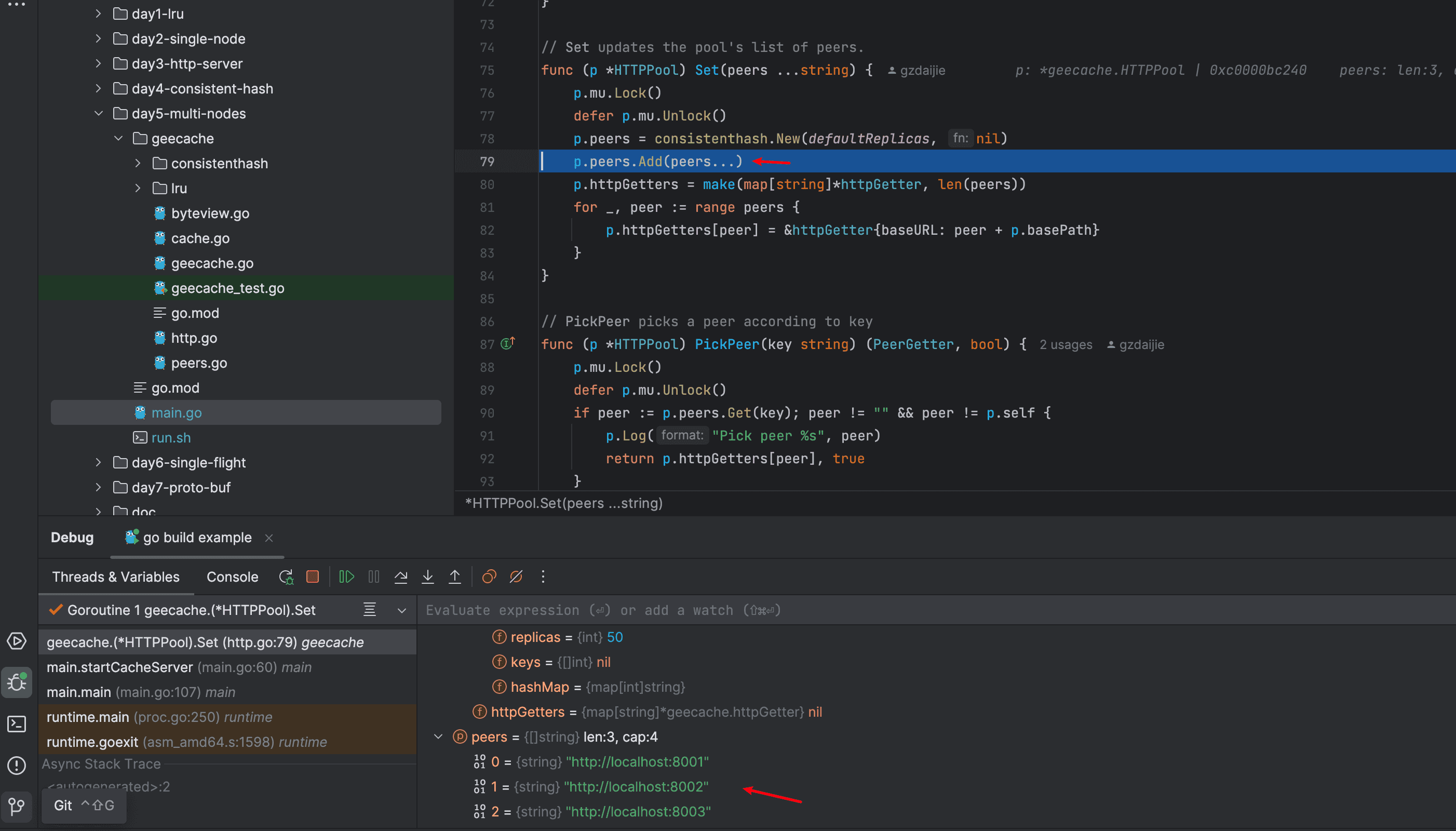
上面这两个图可以结合着理解 一致性哈希在分布式节点的使用
其他
var _ PeerPicker = (*HTTPPool)(nil) 这行代码是用于验证 *HTTPPool 类型是否实现了 PeerPicker 接口的一种方式。
即利用强制类型转换,确保 struct HTTPPool 实现了接口 PeerPicker。这样 IDE 和编译期间就可以检查,而不是等到使用的时候。
防止缓存击穿
背景
缓存雪崩:缓存在同一时刻全部失效,造成瞬时 DB 请求量大、压力骤增,引起雪崩。缓存雪崩通常因为缓存服务器宕机、缓存的 key 设置了相同的过期时间等引起。
缓存击穿:一个存在的 key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时 DB 请求量大、压力骤增。
缓存穿透:查询一个不存在的数据,因为不存在则不会写到缓存中,所以每次都会去请求 DB,如果瞬间流量过大,穿透到 DB,导致宕机。
在分布式节点中有以下使用结果
#!/bin/bash
trap "rm server;kill 0" EXIT
go build -o server
./server -port=8001 &
./server -port=8002 &
./server -port=8003 -api=1 &
sleep 2
echo ">>> start test"
curl "http://127.0.0.1:9999/api?key=Tom" &
curl "http://127.0.0.1:9999/api?key=Tom" &
curl "http://127.0.0.1:9999/api?key=Tom" &
wait2023/11/22 09:29:09 geecache is running at http://0.0.0.0:8001
2023/11/22 09:29:09 geecache is running at http://0.0.0.0:8002
2023/11/22 09:29:09 fontend server is running at http://0.0.0.0:9999
2023/11/22 09:29:09 geecache is running at http://0.0.0.0:8003
>>> start test
2023/11/22 09:29:11 [Server http://0.0.0.0:8003] Pick peer http://0.0.0.0:8002
2023/11/22 09:29:11 [Server http://0.0.0.0:8003] Pick peer http://0.0.0.0:8002
2023/11/22 09:29:11 [Server http://0.0.0.0:8003] Pick peer http://0.0.0.0:8002
2023/11/22 09:29:11 [Server http://0.0.0.0:8002] GET /_geecache/scores/Tom
2023/11/22 09:29:11 [SlowDB] search key Tom
2023/11/22 09:29:11 [Server http://0.0.0.0:8002] GET /_geecache/scores/Tom
2023/11/22 09:29:11 [GeeCache] hit
2023/11/22 09:29:11 [Server http://0.0.0.0:8002] GET /_geecache/scores/Tom
2023/11/22 09:29:11 [GeeCache] hit
630630630对着 api 请求了 三次,8003 向 8002 发了三次请求
本次来实现一个叫作 singleflight 的包来解决这个问题,做到只对远端进行一次请求
方案
从实现上来看,就是对向远端请求的那个流程加锁
func (g *Group) load(key string) (value ByteView, err error) {
// each key is only fetched once (either locally or remotely)
// regardless of the number of concurrent callers.
viewi, err := g.loader.Do(key, func() (interface{}, error) {
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err = g.getFromPeer(peer, key); err == nil {
return value, nil
}
log.Println("[GeeCache] Failed to get from peer", err)
}
}
return g.getLocally(key)
})
if err == nil {
return viewi.(ByteView), nil
}
return
}实现如下
package singleflight
import "sync"
// call is an in-flight or completed Do call
type call struct {
wg sync.WaitGroup
val interface{}
err error
}
// Group represents a class of work and forms a namespace in which
// units of work can be executed with duplicate suppression.
type Group struct {
mu sync.Mutex // protects m
m map[string]*call // lazily initialized
}
// Do executes and returns the results of the given function, making
// sure that only one execution is in-flight for a given key at a
// time. If a duplicate comes in, the duplicate caller waits for the
// original to complete and receives the same results.
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}
两个锁
- mu 来处理对 group m 的操作
- wg 来实现对一个 key 只执行一次函数,其余的等待这个函数请求的结果